ニーズ
Tensorflowのloss functionデフォールトはy_trueとy_predだけで損失を計算する,この中でy_trueは正解値,y_predは予測値となる。
PPOアルゴリズムのActorNNの損失を計算するとき、必要するデータはy_trueとy_predだけではなく、他のNNからの予測値、Advantage値などを弁用して損失を計算する。
尝试
まずはこの方の方法,NNを構築する時、複数のInputを作成し、本物のInput以外のInputは、LossFunctonの引数とする。LossFunctionを導入する同時にそのInputをLossFunctionの引数として使用する。 ソース以下:
|
|
結果
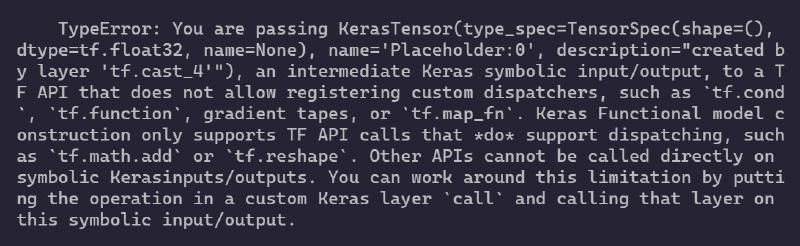
まぁタイトル画像通りエラーだね、KerasTensor型がpassingできないってこと,詳細は以下:
TypeError: You are passing KerasTensor(type_spec=TensorSpec(shape=(), dtype=tf.float32, name=None), name='Placeholder:0', description="created by layer 'tf.cast_4'"), an intermediate Keras symbolic input/output, to a TF API that does not allow registering custom dispatchers, such as `tf.cond`, `tf.function`, gradient tapes, or `tf.map_fn`. Keras Functional model construction only supports TF API calls that *do* support dispatching, such as `tf.math.add` or `tf.reshape`. Other APIs cannot be called directly on symbolic Kerasinputs/outputs. You can work around this limitation by putting the operation in a custom Keras layer `call` and calling that layer on this symbolic input/output.
その後print法でInputからもらったデータはすべてKerasTensor型、だがlossfunctionではtensorflowのTensor型が必要らしい。同じトラブルはこのTensorflowのスレッドもあるTensorflowのバージョンによってInputのデータ型が違うみたい、ソース以下:
|
|
|
|
解決法
結局この問題のアンサーの二番目の方法を使った。LossFunctionが必要の引数をy_trueの中に隠してfitするときに渡す。 ものと答えソース以下:
|
|
自分の解決法:
|
|
今回使ったリンク
ProximalPolicyOptimizationContinuousKeras
Custom loss function is not working #43650
Custom loss function in Keras based on the input data
役に立てないけど参考になりそうなリンク
TypeError: Cannot convert a symbolic Keras input/output to a numpy array. #47311
Use layer output in keras custom loss
How to Convert Keras Tensor to TensorFlow Tensor?
Keras custom loss function: Accessing current input pattern
Passing additional arguments to objective function #2121
How to write a custom loss function with additional arguments in Keras
Recieve list of all outputs as input to a custom loss function. #14140