需求
Tensorflow中的loss function默认只能使用y_true和y_pred来计算损失值,其中y_true为真实值,y_pred为预测值。
在PPO算法计算actor网络的loss时,需要的不仅仅是y_true和y_pred,还需要用到来自另一网络的预测值,Advantage等来计算loss。
尝试
首先我尝试了这位dalao的方法,在网络输入中事先创建loss function所需要的Input,在引入我的loss function时将其引入。 简略代码如下:
|
|
结果
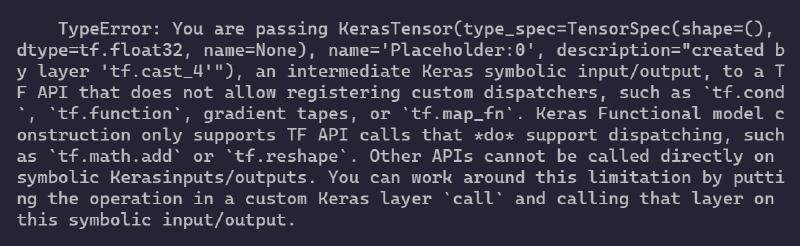
结果就如本篇标题图片所示,提示不能传递KerasTensor,具体错误以下:
TypeError: You are passing KerasTensor(type_spec=TensorSpec(shape=(), dtype=tf.float32, name=None), name='Placeholder:0', description="created by layer 'tf.cast_4'"), an intermediate Keras symbolic input/output, to a TF API that does not allow registering custom dispatchers, such as `tf.cond`, `tf.function`, gradient tapes, or `tf.map_fn`. Keras Functional model construction only supports TF API calls that *do* support dispatching, such as `tf.math.add` or `tf.reshape`. Other APIs cannot be called directly on symbolic Kerasinputs/outputs. You can work around this limitation by putting the operation in a custom Keras layer `call` and calling that layer on this symbolic input/output.
随后用print大法发现从Input层传递获取的数据都是KerasTensor型,而不是lossfunction中需要的tensorflow的Tensor型。相同问题出现在Tensorflow的该讨论串,根据Tensorflow各版本不同,从Input来的数据型貌似不同,代码如下:
|
|
|
|
解决方案
最终我使用了这个问题的答案的第二个方法,将lossfunction所需的argument打包进y_true里暗度陈仓进lossfunction。
原文代码如下:
|
|
我的简略代码如下:
|
|
文中所使用的链接如下
ProximalPolicyOptimizationContinuousKeras
Custom loss function is not working #43650
Custom loss function in Keras based on the input data
本次并未用上但是有可能有参考的链接
TypeError: Cannot convert a symbolic Keras input/output to a numpy array. #47311
Use layer output in keras custom loss
How to Convert Keras Tensor to TensorFlow Tensor?
Keras custom loss function: Accessing current input pattern
Passing additional arguments to objective function #2121
How to write a custom loss function with additional arguments in Keras
Recieve list of all outputs as input to a custom loss function. #14140