概要
看了很多介绍发现PPO(Proximal Policy Optimization)这个算法非常有趣,并且在复杂环境中据说会有很好的表现,之前也只接触过Value-Based Reinforcement Learning,所以想要从PPO来着手试试看Policy-Based。
在学习了莫凡老师文章:Distributed Proximal Policy Optimization (DPPO)后开始实操,本来想偷懒直接ctrl-C+V直接搬过来结果发现莫凡老师的环境居然是Tensorflow1.x。于是只能老老实实重写了。
前置技能
Tensorflow 2.x
Reinforcement Learning基础知识
Actor-Critic基础理解
大概就这么多?
代码实现
使用环境是Tensorflow 2.8 Python 3.9.7,在实现中加入了一些自己的理解,变量也有一些和莫凡老师不一样。
其中OldActorNN应该是没必要去另外创建一个的,计算ratio的时候用之前的记录就可以,这里就···懒得改啦。
以下代码:
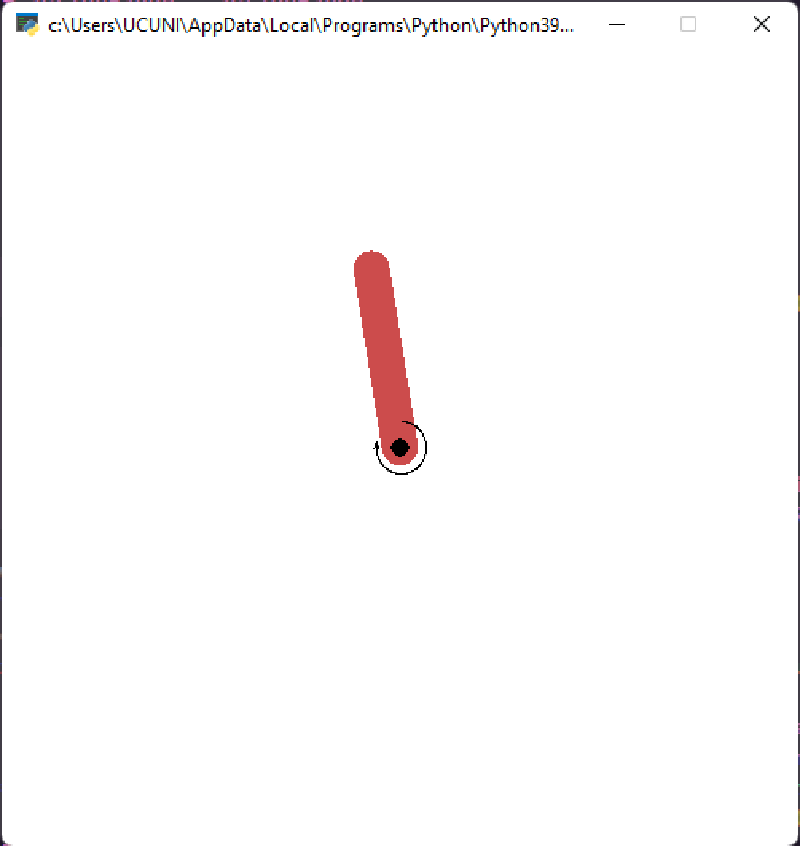
Solve Pendulum-v0 with PPO use Tensorflow2.8
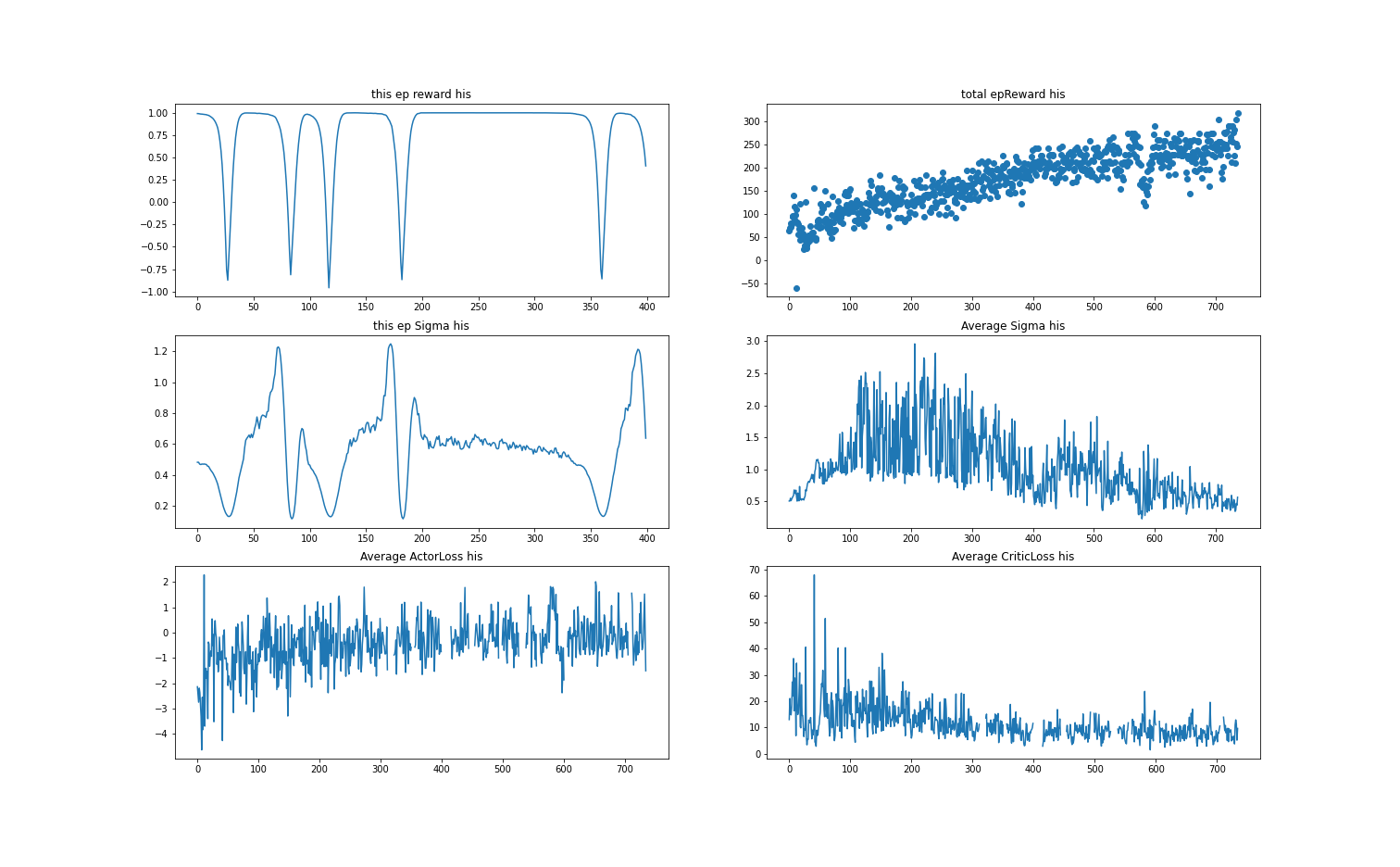
我把reward该到了-1~1左右,所以当完全旋转的时候total_reward大概是150左右。total_reward在250左右已经开始可以长时间立起棒子,算是几乎成功了,再调整一下参数应该可以实现更快更好的效果。
实现结果:
看了大概会很有帮助的连接
莫凡老师的原文
Distributed Proximal Policy Optimization (DPPO)
我的基础学习笔记
Reinforcement Learning基础知识分享与学习笔记
LossFunction实现的灵感来自
Deep Reinforcement Learning Algorithms implemented with Tensorflow 2.3
LossFunction我的实现方法
Tensorflow2.8中创建带其他参数的损失函数