概要
近期阅读了这篇文章 What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study ,本文探索了PPO policy loss, 网络结构, 初始化和转换策略等方面的具体内容。
主要内容
1. Policy Losses
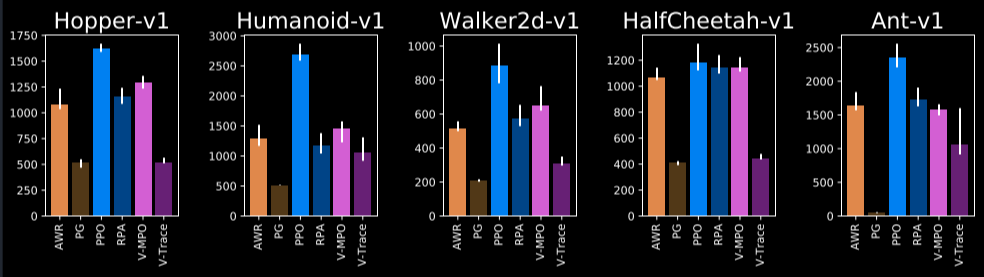
- 使用PPO的policy loss策略。
- PPO clip首先设置为0.25,但也可以根据需要尝试更低或更高的值。
2. Networks Architecture
- 分离的actor和critic在四个环境中都展现了更好的性能。
- 两层的网络结构在所有测试环境中对于actor和critic都是有效的。
- 激活函数中,tanh最为出色,而relu的表现相对较差。
3. Initialization & Transformation
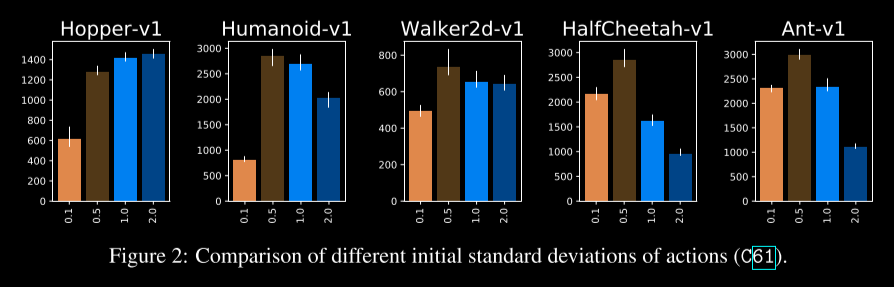
- 最后的策略层的权重初始化为原始值的1/100。
- 使用softplus将网络输出转化为动作的标准差,并在其输入中添加一个负偏移量。
- 对于不深的网络,推荐使用tanh作为激活函数。
- 建议使用宽的critic MLP。
4. Observation Normalization
- 推荐使用标准化的观察方法。
5. Other Techniques
- 使用GAE策略,并避免使用PPO风格的loss clipping。
- gamma值设为0.99似乎是最佳选择。
- 多次遍历经验对于良好的样本复杂性是关键。
6. Optimizer
- Adam优化器的表现十分出色,特别是当momentum beta设置为0.9,l为0.0003时。
- 线性衰减的学习率也可以为模型性能带来提升。